硅云帮助文档中心
搜索文档
热门搜索词:
产品简介
产品定价
入门指南
经典案例
快照
常见问题
知识拓展
名词解释
API参考
云服务器访问很卡是什么原因?
本文档主要讲解如何快速、准确排查云服务器卡顿的原因,如对此文档内容有任何问题请联系硅云人工在线客服。
排查方法
云服务器如出现明显卡顿现象时可以从两个方面来排查,依次是网络质量、硬件性能。
注:如果此文档无法解决您的问题,请联系硅云人工在线客服获得帮助,客户将协助您快速排查原因。
1、网络带宽排查
首先排查网络质量的影响是非常必要的,约有60%的卡顿是网络连通性不佳导致。
检测方法:本地设备ping服务器,假设你的服务器公网IP是 1.1.1.1,执行命令:
ping 1.1.1.1 -n 100 -w 500 #这条命令是对服务器ping 100次,结束后可以查看丢包率,测试前请前往硅云管理控制台-安全组设置处放行ICMP协议、且确保云服务器系统内已设置允许ICMP协议,否则无法ping通。
如结果显示丢包率在5%以内(偏远地区、晚高峰等时段,中国香港及海外服务器的丢包率可以放宽至8%以内)说明网络质量较好,丢包率在10%以上(中国香港及海外服务器为15%以上)说明网络质量欠佳(或网络存在拥堵,也可能是云服务器的带宽已满载)。如有疑问请联系硅云人工在线客服。(如需检查云服务器带宽资源是否已满载,请参考以下情况2的“监控”项入口)
2、排查硬件资源性能(注:负载异常高的机子要重点检查此项)
在硅云管理控制台【我的产品】>【云服务器】>【实例列表】页面,找到“监控”项,可以查看实例的CPU内存、网络等资源负载统计图,以便您分析实例的资源使用情况。
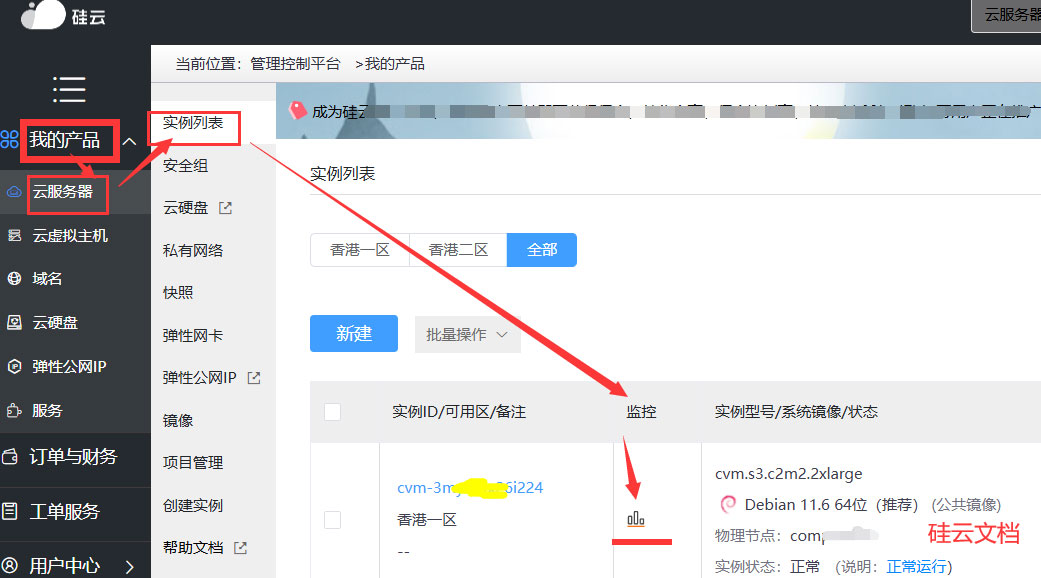
对于Linux系统服务器来说,外部抓取的监控获取的内存RAM使用率并不准确(因Linux系统通常会将缓存和缓冲区也算作已使用的内存),我们通常需要进一步检查,请登录云服务器系统,检查内存和CPU情况,参考如下。
以Linux系统(Debian/Ubuntu/CentOS)为例,执行命令:
top #执行top命令 1 #按1可以切换查看每个CPU核心的情况 c #按C可以切换查看每个进程占用CPU、内存的情况
top命令可以查看系统的实时硬件情况,关键指标有三项:CPU使用率、内存使用率、磁盘IO wait。
案例1:因内存RAM不足,已开始大量使用swap虚拟内存,导致宝塔卡顿,系统负载非常高。
如下图是一个客户的示例:某位博客主发现自己的网站访问很慢,云服务器配置是1核1G,安装的是宝塔Linux面板,宝塔面板首页显示的系统负载很高(运行堵塞,是不是飙到100%)、但CPU和内存占用却并不高,只存放了一个WordPress博客,测试网络也没有问题。对于这种CPU使用率和内存使用率上都看不出问题,但是系统负载长时间处于1以上(1表示100%;注:云服务器的CPU是N核心的,那么正常负载就应该在N以下,达到N就说明满载,超过N就说明系统负载过重),尤其是要关注IOwait指标(IOwait 是指 CPU空闲且有 磁盘 I/O 任务 所占的时间比例,该项数值越大,说明大量磁盘IO过于繁忙)。
使用top命令的结果如下图所示,异常之处就是磁盘IO wait长时间处于高位,达到80%以上,磁盘IO wait负载超过20就需要格外警惕,这会导致读取文件变得很慢,访问自然会变得很卡。根据后边的排查,该用户安装宝塔面板时,默认启用了swap虚拟内存交换分区(即内存不够用时,会把一部分磁盘当做内存使用,目前新版本宝塔都会默认开启swap功能),正是因为内存不够,系统开始使用swap虚拟内存,导致磁盘读写变拥堵,iowait指标提升,现象就是CPU使用并不高,但因为磁盘IO被swap功能大量占用,大量任务在等待磁盘IO,本质上这是内存RAM不足。经过此次分析后,该用户将内存RAM升级到了2G即解决了此问题。

案例2:内存RAM严重不足,系统开始大量杀死各类进程,导致网站访问异常卡顿、远程连接操作非常困难。
某位用户反馈云服务器(2核4G实例)每天必卡两三次,里边的网站在上午十点、下午四点、晚上九点左右都得卡一次(十几分钟到半个小时),每次卡顿的时候网站系统的后台无法打开,大量访客反馈无法访问服务器内的网站,重启系统也不管用。登录【硅云控制台】云服务器-实例列表右侧的“VNC控制台”,可以看到系统出现大量的报错/警告信息,如下图所示,大量“Out of memory: Killed process...”信息,表示系统因为可用内存RAM不足,已经在尝试杀进程缓解内存不足了。
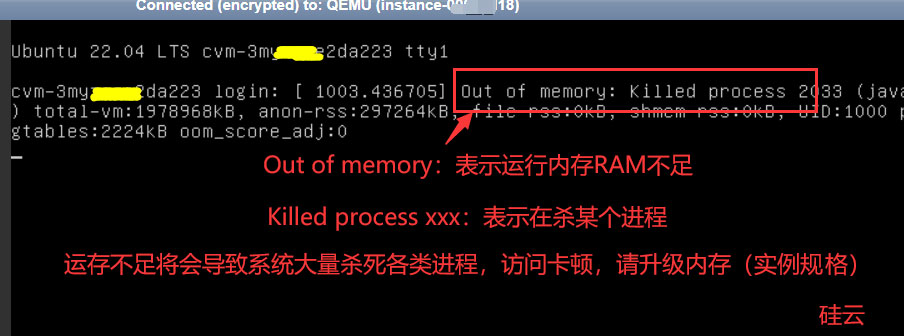
此后该用户将内存从4G升级到了8G,在高峰期也在未出现过间断性卡顿的现象。
您对该文档有什么建议?
本文导航
